七月算法 大数据工程师集训营课程介绍:
本期集训营实战项目,涵盖集群搭建、hive优化、数据仓库搭建、数据采集平台、离线计算平台、实时计算平台、多维分析平台、直播、短视频APP用户行为分析、日志监控(搜索、分析、报警)平台等一线互联网实用案例。从Hadoop起步,一上来就实战BAT工业项目。且根据集训营实战项目,将涉及到的关键知识点和项目经历优化到您的简历中。
本大数据集训营从Hadoop基础讲解,贯穿数据采集、传输、存储、计算、展示等各个环节,着重讲解企业中如何使用spark、MapReduce、hive、flume、sqoop等各个组件,并附有经典企业案例讲解,案例均来自一线互联网工业项目。
另,讲师团队堪称大厂豪华级大数据专家讲师团队,且根据最近的大数据人才需求,加入elasticsearch和数据仓库模型等内容,以及设计了三大企业级项目,并标准化项目流程:
a、设计与搭建基于Hive、Presto的数据仓库与OLAP分析引擎
b、Flink实战——直播、短视频APP用户行为分析
c、ELK+Spark实现一个错误日志监控(搜索、分析、报警)平台
最后,在第八阶段设置了大数据求职面试辅导,包括大数据面试求职准备工作讲解、常见大数据面试题目解析等内容。
一切为了大家更好的就业、转型、提升。
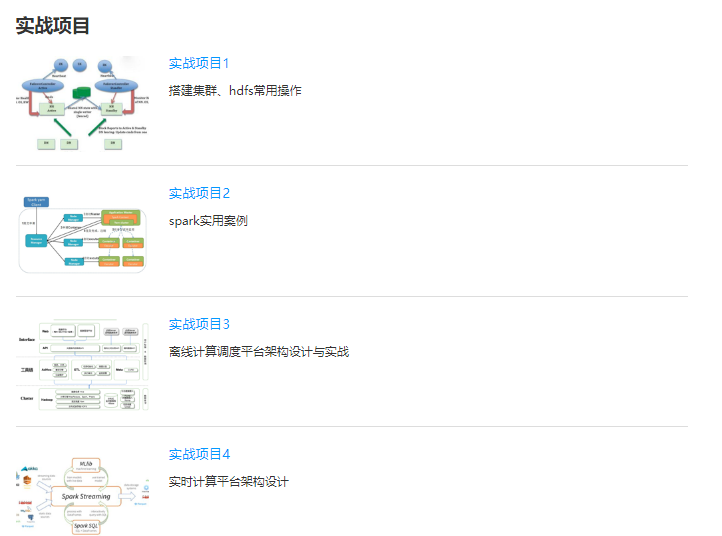
七月在线大数据工程师集训营课程介绍图
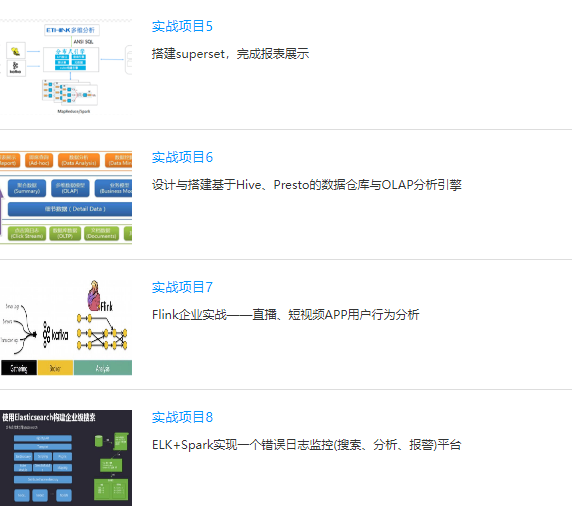
七月在线大数据工程师集训营课程介绍图
课程大纲:
第一阶段:大数据与Hadoop 基础(HDFS与YARN)
在线视频:大数据与Hadoop生态介绍
1-为什么要学大数据
2-大数据技术发展史
3-大数据的应用以及未来
4-Hadoop生态圈介绍
5-Hadoop框架演变与核心组件
在线实训:搭建HDFS伪分布式集群
在线视频:大数据存储系统HDFS
1-HDFS的设计目的与系统结构
2-namenode管理元数据的机制
3-hdfs的写入过程分析
4-hdfs的读取过程分析
5-大集群hdfs的使用经验
在线实训:搭建Zookeeper、HDFS、YARN的分布式集群
在线视频:分布式资源管理框架Yarn
1-为什么使用yarn
2-yarn的设计与系统结构
3-yarn任务提交流程
4-yarn的常用操作
5-大集群yarn的使用经验
在线视频:分布式计算框架MapReduce与Hive SQL
1-MapReduce发展与简介
2-Mapper、Reduce执行过程详解
3-MapReduce原理解析
4-Job、Driver原理及使用原理
5-Hive原理及介绍
6-Hive SQL常规操作、优化与技巧
第二阶段:数据采集工具与消息队列Kafka
在线视频:数据收集工具Flume、Beats介绍与原理
1-Flume的介绍及其架构
2-Flume不同模式对比分析
3-Flume安装部署
4-Beats 的介绍及安装部署
在线实训:Flume收集日志数据到HDFS或者Kafka
在线视频:数据库同步工具Alibaba Canal介绍与原理
1-Canal简介
2-Canal架构原理讲解
3-Canal的的搭建和使用
在线实训:通过Canal将MySql数据导入到HDFS中
在线视频:高吞吐消息队列Kafka介绍(一)
1-Kafka使用场景介绍
2-Kafka基本介绍及概念讲解
3-Kafka架构及原理介绍
4-Topic的管理与Producer与Consumer的使用
5-Kafka集群管理
在线视频:分布式数据库Hbase
1-mysql与nosql
2-Hbase的介绍及其发展
3-Hbase中的物理模型与存储模型
4-Hbase读写流程分析
5-Hbase的shell命令以及java API
6-分布式HBase集群的搭建与使用
第三阶段:Spark流式计算实践
在线视频:spark技术栈发展概述与spark应用开发API介绍
1-Spark2.x 技术栈概述
2-Spark在大公司的应用
3-Spark 核心概念讲解
4-RDD的分区与依赖
5-RDD API中的Transformation讲解
6-RDD API中的Action讲解
在线实训:Spark RDD API分布式构建搜索引擎的分布式倒排索引
在线视频:流式计算简介及spark streaming
1-Spark streaming | Storm | Flink | Structured streaming 全面对比
2-Spark Streaming运行原理
3-Spark Streaming高层抽象DStream
4-Structured Streaming运行原理简介
在线实训:Kafka + Spark Streaming构建实时监控大屏
在线视频:流式计算实战
1-实时大数据架构简介
2-实时计算平台架构设计及选型方法
3-实时计算实践难点剖析,高qps及性能瓶颈分析
在线视频:spark运行模式及原理
1-spark运行模式
2-spark执行过程讲解
3-spark rdd内部原理详解
4-spark广播变量与累加器讲解
第四阶段:深入Spark SQL与核心原理
在线视频:Spark sql讲解
1-spark sql 发展史
2-spark sql 1.X 与 2.X
3-spark sql 运行原理分析
4-spark sql 逻辑计划原理讲解
5-spark sql 物理计划原理讲解
6-dataset与dataframe讲解
7-spark sql 自定义注册函数udf开发
8-spark thrift server讲解
在线实训:基于spark sql 2.4.0 的王者荣耀英雄分析
在线视频:Spark集群监控与问题排查
1-spark web ui讲解
2-spark应用监控与分析
3-spark history server原理剖析
4-spark metrics 监控
在线实训:spark history server搭建部署; 从监控入手进行日志查错与优化
在线视频:Spark core核心讲解与Spark性能调优
1-Spark Shuffle三种模式详解
2-Spark内存管理剖析
3-Spark应用资源管理
4-Spark RDD存储管理
5-Spark开发、资源、数据倾斜与内存的调优
在线视频:使用Spark开发一套通用的流和批计算引擎
1-通用计算引擎的处理流程分析
2-实现插件化系统的常用设计模式与Java库
3-基于Spark的计算引擎的设计与实现
第五阶段 企业级项目:设计与搭建基于Hive、Presto的数据仓库与OLAP分析引擎
在线视频:数据仓库基础
1-OLTP与OLAP的介绍与区分
2-关系模型与纬度模型深入介绍
3-海量数据上的维度表、事实表设计
4-离线数据仓库的搭建与维护
在线视频:数据仓库的数据治理与任务调度
5-列示存储及Hive常用文件格式ORC,Parquet介绍
6-任务调度工具Azkaban在数据仓库中的应用
7-数据仓库的数据质量管理(元数据管理、质量保障原则与方法、解决数据丢失延迟)
在线视频:OLAP分析场景下的技术架构
8-OLAP场景下的大数据技术栈
9-Presto的架构与原理分析
10-Presto SQL的使用方式与性能优化
11-Presto Connector开发指南
第六阶段 企业级项目:Flink实战实战——直播、短视频APP用户行为分析
在线视频:Flink基础介绍
1-流批计算的趋势与两大计算框架(Flink, Spark)的比较
2-Flink编程模型与API的使用
3-Flink SQL与Table API
在线视频:Flink核心特性讲解
4-Flink核心特性的原理与应用(Window计算,状态与容错)
5-Flink应用的部署与监控
6-直播、短视频业务的数据模型及核心业务指标
在线视频:开发用户行为分析的Flink程序
7-使用Flink搭建实时数据流来分析直播、短视频业务指标
8-使用Flink SQL搭建离线数据仓库来分析直播、短视频业务指标
9-开发业务核心指标监控大屏
第七阶段 企业级项目:ELK+Spark实现一个错误日志监控(搜索、分析、报警)平台
在线视频:日志平台介绍及Elasticsearch基础
1-错误日志监控平台的架构及技术选型
2-Elasticsearch 功能、应用场景、分布式架构介绍
3-Elasticsearch的Index API,Search API, Query DSL使用
在线视频:错误日志平台搭建
4-日志收集Filebeats, Logstash 的使用介绍
5-数据可视化工具Kibana介绍
6-使用Elasticsearch、Logstash、Kibana搭建错误日志监控平台
在线视频:日志平台架构优化与Spark集成
7-在Elasticsearch中集成Spark流式日志处理
8-用Spark SQL实现基于Elasticsearch的日志离线SQL分析
9-Elasticsearch的集群管理API使用
10-Elasticsearch 分布式读写和聚合原理讲解
第八阶段: 大数据求职面试辅导
在线视频:大数据面试求职准备工作讲解
1-大数据职业规划介绍
2-大数据面试知识点大纲整理
3-如何准备简历
在线视频:常见大数据面试题目解析
1-大数据算法题目解析
2-HDFS、Yarn、MapReduce、Hive面试题目解析
3-Spark、Flink面试题目解析
4-HBase、Elasticsearch面试题目解析
课程目录:
——/七月online-大数据工程师集训营 「3月下旬新增三大实战项目,且标准化项目流程」/ ├──01、第一阶段大数据与Hadoop 基础(HDFS与YARN) | ├──01、在线视频:大数据与Hadoop生态介绍.mp4 290.09M | ├──02、在线视频:大数据存储系统HDFS.mp4 336.58M | ├──03、在线视频:分布式资源管理框架Yarn.mp4 363.57M | └──04、在线视频:分布式计算框架MapReduce与Hive SQL.mp4 254.48M ├──02、第二阶段数据采集工具与消息队列Kafka | ├──01、在线视频:数据收集工具Flume、Beats介绍与原理.mp4 136.64M | ├──02、在线视频:数据库同步工具Alibaba Canal介绍与原理.mp4 133.22M | ├──03、在线视频:高吞吐消息队列Kafka介绍(一).mp4 307.64M | ├──04、在线视频:分布式数据库Hbase.mp4 291.15M | └──05、在线视频:数据采集工具与消息队列实战.mp4 1.12G ├──03、第三阶段 Spark流式计算实践 | ├──01、在线视频:spark技术栈发展概述.mp4 217.85M | ├──02、在线视频:流式计算简介及spark streaming.mp4 336.08M | ├──03、在线视频:流式计算实战.mp4 384.49M | └──04、在线视频:spark运行模式及原理.mp4 389.33M ├──04、第四阶段深入Spark SQL与核心原理 | ├──01、在线视频:Spark sql讲解.mp4 435.63M | ├──02、在线视频:Spark集群监控与问题排查.mp4 440.56M | ├──03、在线视频:Spark core核心讲解与Spark性能调优.mp4 264.83M | └──04、在线视频:使用Spark开发一套通用的流和批计算引擎.mp4 310.13M ├──05、第五阶段 企业级项目:设计与搭建基于Hive、Presto的数据仓库与OLAP分析引擎 | ├──01、在线视频:数据仓库基础.mp4 285.32M | ├──02、在线视频:OLAP分析场景下的技术架构.mp4 312.96M | └──03、在线视频:数据仓库的数据治理与任务调度.mp4 358.35M ├──06、第六阶段 企业级项目:Flink实战——直播、短视频APP用户行为分析 | ├──01、在线视频:Flink基础介绍.mp4 484.85M | ├──02、在线视频:Flink核心特性讲解.mp4 329.47M | └──03、在线视频:开发用户行为分析的Flink程序.mp4 387.65M ├──07、第七阶段 企业级项目:ELK+Spark实现一个错误日志监控(搜索、分析、报警)平台 | ├──01、在线视频:日志平台介绍及Elasticsearch基础.mp4 329.68M | ├──02、在线视频:错误日志平台搭建.mp4 470.00M | └──03、在线视频:日志平台架构优化与Spark集成.mp4 312.72M └──08、八阶段 大数据求职面试辅导 | ├──01、在线视频:大数据面试求职准备工作讲解.mp4 342.93M | └──02、在线视频:常见大数据面试题目解析.mp4 330.95M









